
by Shawn Burke, Ph.D.
Introduction
I’ve been at this for a while. No, not writing Science of Paddling articles, although that’s been an ongoing joy for me. What I’ve been at for so long is trying to understand how things work. Like many engineers, some of my first memories are of taking things apart and putting them back together. For me it was my aunt’s percolating coffee maker, over and over, when I was three years old. I graduated to bad arc welding when I asked, “Gee, what happens when I bridge the two metal thingies of a partially inserted electrical plug with this pocketknife?” My father was not amused. Then, when I learned that fireworks were illegal, I wondered, “Can I make my own?” I remember my mom’s reaction when a prototype blew up in my face during manufacture, leaving me with a bloody eyelid and ringing ears: “I told you so.”
More recently, I’ve been working to understand why things work. This butts up against the philosophical field of ontology, or the nature and causes of being. Since speculation about that leads nowhere – mostly to hours and hours of chasing your own tail – I’ve backed off from the “ontological event horizon.” These days I try to dig beneath the science, mathematics, and engineering I learned in school to understand where it came from, what assumptions were made in developing it, and how can I use that information to better understand the world. Or at least paddling. Gotta start somewhere.
Which leads me to position, velocity, and force. We all know what these are, right?
Right?
So in this installment of the Science of Paddling series we’ll consider these fundamental parameters, and the assumptions we make all day long about them. We’ll use the paddle equation from my book, also found in Part 11: About the Bend, as a platform for discussion. We’ll consider the implications for paddling power measurement. Along the way we’ll draw from Isaac Newton’s 3rd Law of Motion, as well as from Galileo via Newton as we ground ourselves in reference frames.[1]
Here or There
As shown in Chapter 6 of The Science of Paddling,[2] the relationship between paddle propulsive force and velocity can be written as

Where 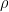
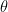

This equation represents the instantaneous propulsive force in the direction of travel. Why? First, because of the cosine function. The drag coefficient synopsizes the complex fluid flow around a paddle blade in a single number. It is measured either in a wind tunnel or water tank, or computed via numerical simulation, depends on the angle the blade makes to the water. For simplicity it is usually measured or computed for flow perpendicular (aka, “normal”) to the blade’s power face. A cosine dependence is added to account for changes in angle. When the blade is vertical the cosine function goes to one, so the drag effect equals its normal incidence value. Check! For other angles the drag coefficient is some fraction of that, weighted by the cosine.
Where does that cosine variation come from? From many, many tests run by engineers and engineering students in wind tunnels and water tanks. It fits the data. But does that model always work? Buried in the underlying fluid mechanics is a fun phenomenon called the stagnation point. The stagnation point is the location on an object immersed in a fluid where the incoming streamlines part. Above the stagnation point adjacent streamlines bend up, below it they go down, and side-to-side they bend toward their respective sides. If you’ve ever aimed a garden hose at the side of a building you’ve seen this. The drag coefficient model implicitly assumes that the stagnation point doesn’t move when the blade changes angle. Is that always the case? Some paddle manufacturers have gotten very creative with blade shapes to increase their paddle’s “grab” at the catch, and through the power phase. Some combine concave and convex surfaces to achieve this result. Do their stagnation points move with changing blade angle? I have no idea.[3] Does that bother me? Not really. Once things get that specialized you’ve moved away a guiding principle of The Science of Paddling: provide information and insight that applies across a variety of hulls and paddles, rather than to one specific make, model, or design.
So, what about the velocities in our paddle equation? Before we get to that, let’s talk about latitude and longitude. Latitude and longitude are coordinates used to describe positions on spheroidal objects like the Earth. If I said that I was at 44.934235 degrees north latitude and minus 68.645309 degrees longitude you probably wouldn’t think twice about it. Some of you might even know that these coordinates place me in Old Town, Maine, home of Old Town Canoe. But 44.934235 degrees is the same as saying “tall” or “short.” Tall or short compared to what? This is because latitude is a quantity that is always referenced to something else. By convention that reference is the equator, the imaginary line drawn around the planet’s middle.[4] The same goes for longitude, which by convention is referenced to the “prime meridian” longitudinal line running through Greenwich, England. Implicit in any position is its reference to some other position.
The same goes for speed, the scalar magnitude of velocity. If I say I was driving at 100 km/hr you might be unimpressed if I did so on an interstate highway, and surprised if I did it in a school zone. But implicit in that number is that driving speed is referenced to zero km/hr. Big whoop, right?
Well, it gets more interesting on water if you’re a paddler, or in the air if you’re a pilot. If you’re flying a Boeing 787-9 from San Francisco to Singapore, a roughly seventeen-hour flight, you care very much about the difference between your airspeed and your speed over ground. Airspeed is your speed referenced to any headwind or tail wind; think of it as the speed of airflow over the jet. Your speed over ground, which determines your arrival time as well as the amount of fuel you need at takeoff, can be thought of as your “GPS speed.” It’s your actual speed referenced to an inertial reference frame, aka, the Earth.
Inertial reference frames are reference coordinates that don’t accelerate. They can move at any constant velocity and still be considered inertial. A special case is the zero-velocity reference frame, which we attribute to the Earth beneath our feet.[5] Now the velocities in our paddle equation, vpaddle and vhull, are often expressed in reference to the Earth frame; I do this in my book. It’s convenient because any inertial sensor – like an accelerometer – placed on the paddle blade or hull returns data referenced to the Earth frame.
So, what about adopting a different reference frame? For example, let’s adopt the paddle blade’s frame of reference.[6] Imagine that you’re sitting on the blade (figuratively). In that reference frame the blade’s velocity is zero. Is there still a paddle propulsive force?
Yes, there’s still a propulsive force. Why would there not be? All you’ve done is move from an Earth-centric reference frame to a different one. This change of reference frames is called a Galilean Transformation, after Galileo – even though Newton invented it.
Let’s next adopt the hull’s frame of reference, which I sometimes call the paddler’s reference frame. We’re all familiar with the paddler’s point of view: it seems like water is coming toward our hulls rather than the opposite. In this reference frame the hull’s velocity is zero. Is there still a paddle force? Of course there is! We’ve all paddled know that there is still a paddle propulsive force. We’ve merely moved reference frames (again).
Finally, let’s adopt an arbitrary inertial reference frame that has velocity vreference. How does that impact our paddle equation? The only change will be in the velocity term, which now becomes:
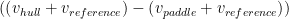
vreference is added to both terms to perform a Galilean transformation[7] to its coordinate system. Because our paddle equation is expressed in terms of the difference of paddle blade and hull velocities, we see that vreference falls out of the equation, leaving us with
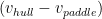
What does this imply? That the paddle propulsive force is independent of the choice of inertial reference frame. This is a big deal in many ways, one of which we’ll discuss in the next section. By contrast, the velocity of any object – hull, paddle, kingfisher, UFO, etc. – depends on the choice of inertial reference frame.
For those of you who took a dynamic systems course as an undergraduate, you may remember that variables were categorized into two buckets: through variables, and across variables. An across variable is any variable measured or defined in reference to some other quantity. This includes displacement, velocity, charge, voltage, etc. For example, voltage is often referenced to ground. By contrast, through variables are not referenced in this way. This included force, current, etc.
A few tidbits about the paddle equation. First, the paddle force is proportional to the square of the difference in velocities. Since the water density, drag coefficient, blade area, the number one-half, and the cosine function during the power phase are all positive quantities, the propulsive force is a “positive semi-definite” quantity. This is a precise way of saying “zero or some positive number.” Why not negative? Because we assume, by convention, that the paddling propulsive force is in the direction of travel. Often by convention travel is in the positive direction, too. Could we adopt another convention? Of course. It’s just a matter of bookkeeping and keeping track of things.
Next, which direction does the paddle force point in? In the direction opposite the direction of travel. You can feel this in the hull as you paddle. You’re pushing the paddle blade behind you when you paddle forward, and thus pushing on the water. The propulsive force is consequently a reaction force, arising due to Newton’s 3rd Law of Motion of action balancing reaction. Why is this so? Consider the following thought experiment. You’re sitting on a dock on a windless morning, and a hull is in still water, aligned perpendicular to the dock with its stern next to you. You push against the stern, making sure your push is in the direction of and aligned with the hull’s keel line. The hull moves away from you. You’ve provided a propulsive force through your hand(s) and the hull moves in the direction of your applied force. Yes? This means that the paddle propulsive force, which also causes the hull to move away from the paddle blade’s direction of motion, must be a reaction force. Otherwise, the hull would be moving in the same direction as the paddle force, which from centuries of experience we know isn’t true. This is also consistent with conservation of momentum as detailed in Chapter 4 of The Science of Paddling.
Finally, please take another look at the paddle equation found at the beginning of this article. I’m not kidding! Take a look; we’ll wait…
Now, answer me this: Does the difference in velocity between the hull and paddle cause the propulsive force, or does the propulsive force cause the difference in velocity between the hull and paddle?
Most science and engineering students are taught that the right-hand side of an equation represents the input to a system. That’s another convention. But since the equation is an equation – in other words, one side equals the other side – you can just swap the two sides and still satisfy the equation. Does this mean that the propulsive force is now the input? Rearranging the equation is just bookkeeping; why would that have anything to do with which side is the input?
Yeah, I’ve gone all philosophical on you. As to the physics, both answers work. I like to think that the difference in velocities and the paddle force occur together. My answer to which scenario is correct is, “They’re both correct.” Sure, this runs counter to Western logic, which often insists that one thing be the input, and another be the output. It’s more like the four-cornered logic employed by philosophers in Northern India around 2,600 years ago. I kinda like that.
Power vs Impulse
Many folks have asked me about paddling power measurement, probably because we’re all familiar with cycle power taps and similar sensors. I went down that rabbit hole once before and wasted a lot of time trying to get around the laws of physics.[8] Needless to say, physics won.
Power is defined as the product of force and velocity. Since both force and velocity have a direction, we either assume (as we will here) that the force and velocity “point” in the same direction, or compute what in vector mathematics is called a dot product. Here the relevant force is the propulsive force, which by convention points in the direction of motion. We’ll assume that the velocity we use to compute paddling power also points in the direction of motion, making the power computation a simple multiplication. But which velocity do we use? As you’ll see, our discussion of velocity and inertial reference frames wasn’t merely an academic exercise.
Let’s assume that for our power computation we use the paddle blade’s velocity. What happens when we’re paddling into current, and our blade never moves with respect to the Earth’s reference frame during the power phase? In that case our blade velocity precisely cancels the flow velocity. If we’re using an inertial accelerometer or solid-state inertial measurement unit to measure velocity, we’ll predict that the paddling power is zero, even though we’re trying to paddle and move into the current.
Let’s assume that for our power computation we use the hull’s velocity. What happens when we’re paddling into a current, and our hull never moves with respect to the earth’s reference frame? Again, if we’re using an inertial accelerometer or solid-state inertial measurement unit to measure velocity, we’ll predict that the paddling power is zero, even though we’re trying to paddle and move into the current.
As you can see, most generally we need to measure both the hull and paddle blade velocities in the direction of motion, as well as the paddle’s propulsive force in the direction of motion, to compute paddling power. Which means two sensors whose drift and calibration must be accounted for. Since their data may be wirelessly transmitted to a central receiver, we also need to account for time alignment of these two signals, otherwise we’re multiplying time-dependent data that are out of phase. Fun times! You’ll also need an IMU in the paddle so that you can account for the blade angle over time. The paddle force is always perpendicular to the blade’s power face as the paddle rotates through the power phase, while propulsive force is referenced to the direction of travel.
Consider instead impulse, as discussed in Chapter 7 of The Science of Paddling. Impulse is the product of the average paddle propulsion force over the power phase time the power phase’s duration. Impulse specifies a hull’s change in momentum over a stroke, which for a hull of constant mass means the hull’s velocity over that stroke. As we saw above force doesn’t depend on the choice of inertial reference frame; time doesn’t, either. Consequently, an impulse measurement – the product of paddling propulsive force and time – is independent of reference frame. You could be moving upstream, downstream, across stream, or in still water, and impulse doesn’t care. You still need to account for blade angle over time to measure propulsive force and thence impulse in the direction of travel. That’s what solid-state IMUs are for. But velocities aren’t required to measure impulse.
Summary
In this installment of The Science of Paddling series we used the paddle equation as a platform to discuss reference frames, velocities, and forces. We showed that forces are independent of which inertial reference frame you choose. This has implications for paddling power measurement and indicates the utility of impulse measurement as an alternative. You can extend the analysis to include accelerating reference frames. That introduces “fictitious” forces called pseudo forces that lie beyond the remit for this post.
We also posed the question of whether the difference in velocities in the paddle propulsive force equation is the input, or does the propulsive force cause this velocity difference. We can now take that thought experiment further. You could point out, “Well, we hold the paddle and exert forces on the shaft,” which is of course true. And those forces correspond to contractions of muscles (which are movements that give rise to forces), along with movements of our arms, torsos, hips, and legs. Then there’s the force produced by leg drive, which connects us with the boat, as well as forces transmitted through our seat. Which came first? Which of these is the input?
If you go far enough, you’ll have to say the Sun, since that is ultimately our source of energy via the food we eat to power our metabolism and muscles. And the Sun is merely the accretion of material from the formation of the Universe. So ultimately the reason paddling works is because of the Big Bang.
© 2023, Shawn Burke, all rights reserved. For more information, please see our Terms of Use.
- Those of you who’ve studied dynamic systems will get that joke. Yes, it’s a very small joke. ↑
- This form of the equation, which combines equations (6.2) and (6.3) from Chapter 6, appears in the Appendix at page 232. You can order a copy of the book through your favorite online book seller. ↑
- I read about blade “spill” and “slippage” all the time. While I might have some intuitive idea of what these phenomena might be based solely on feel, I try not to use those terms. Why? Because I’ve yet to see them quantified with hard data, or any standardization of these terms based in physics. Give me a number backed by data and we’ll talk. ↑
- More or less. Even the equator’s location is defined by convention since the Earth isn’t perfectly spherical. ↑
- Still, it moves: https://www.youtube.com/watch?v=buqtdpuZxvk . ↑
- This is an example of how science, in this case physics, introduces an observer into the system. For most people this makes no difference; for philosophers of science, it’s a huge deal. ↑
- You could subtract it as well; makes no difference. ↑
- See the book’s ‘Interlude – Tales of Power” following Chapter 7. ↑